카프카 커넥트(Kafka Connect)란
카프카(Kafka)는 프로듀서(Producer)와 컨슈머(Consumer)를 통해 다양한 외부 시스템 데이터를 주고 받으며 메세지 파이프라인 아키텍쳐를 구성한다. 하지만 이러한 파이프라인을 매번 구성하며 프로듀서와 컨슈머를 개발하는 것은 쉽지 않다. 따라서 카프카 메세지로 파이프라인 아키텍쳐를 보다 적은 비용으로 보다 쉽게 구현하게 도와주는 것이 카프카 커넥트(Kafka Connect)이다.

카프카 커넥트는 아파치 카프카의 오픈소스 프로젝트 중 하나로, 카프카와 외부 시스템(DB 등) 간의 파이프라인 구성을 쉽게 해주는 프레임워크이다. 카프카 커넥트는 카프카 클러스트를 기준으로 커넥터를 양방향으로 배치하여 구성할 수 있다. 즉, 외부시스템 → 소스 커넥터 → 카프카 클러스트 → 싱크 커넥터 → 외부시스템과 같은 형태로 아키텍쳐를 구성하며 카프카와 외부시스템을 이어준다.
카프카 커넥트의 특징
카프카 커넥트는 대표적으로 다음과 같은 5가지 특징을 가지고 있다.
- 데이터 중심 파이프라인 : 카프카 커넥트를 이용해 카프카로 데이터를 보내거나, 카프카로 데이터를 가져옴
- 유연성 : 커넥트는 테스트를 위한 단독 모드(standalone mode)와 대규모 운영 환경을 위한 분산 모드(distributed mode)를 제공
- 재사용성과 확장성 : 커넥트는 기존 커넥터를 활용할 수도 있고 운영 환경에서의 요구사항에 맞춰 확장이 가능
- 편리한 운영과 관리 : 카프카 커넥트가 제공하는 REST API로 빠르고 간단하게 커넥트 운영 가능
- 장애 및 복구 : 카프카 커넥트를 분산 모드로 실행하면 워커 노드의 장애 상황에도 메타데이터를 백업함으로써 대응 가능하며 고가용성 보장
카프카 커넥트의 커넥터
카프카 커넥트(connect)는 커넥터로 구성되어있는 프레임워크이며 커넥터를 동작시키는 역할을 한다.
커넥터(connector)는 커넥트 내부의 실제 메시지 파이프라인이며 데이터를 실질적으로 처리한다. 이러한 커넥터는 카프카 클러스터를 기준으로 양쪽에 위치하고 있다. 커넥터에는 일종의 프로듀서의 역할을 하는 소스 커넥터, 컨슈머 역할을 하는 싱크 커넥터가 있다. 이러한 커넥터들은 카프카 커넥트가 제공하는 REST API로 구성할수있다.
- 소스 커넥터 : 외부 시스템에 담긴 데이터를 카프카 클러스터로 담아주는 프로듀서의 역할을 하는 커넥터
- 싱크 커넥터 : 카프카 클러스터에 있는 데이터를 외부 시스템으로 보내는 컨슈머의 역할을 하는 커넥터

다시말해 커넥터들은 각자의 위치에서 데이터를 어디에서 어디로 복사해야 하는지의 작업을 정의하고 관리하는 역할을 한다. 예를들어 RDBMS의 데이터를 카프카로 이동하고 싶으면 JDBC 소스 커넥터가 필요하고, 카프카에 적재되어 있는 데이터를 HDFS로 적재하고 싶으면 HDFS 싱크 커넥터가 필요하다. 운영 환경에서 이용하는 커넥터의 대표적인 예로써는 미러 메이커 2.0, 데비지움(Debezium)등이 있다.

카프카 커넥트의 내부 동작 원리
카프카 커넥트는 내부적으로 워커 단위로 이루어져있다. 워커는 카프카 커넥트 프로세스가 실행되는 서버 또는 인스턴스를 의미한다. 이러한 워커 내부는 커넥터와 테스크로 이루어져있다.
- 커넥터 : 데이터를 어디에서 어디로 복사하는지를 담당
- 테스크 : 커넥터가 정의한 작업을 직접 수행
카프카 커넥트는 다수의 커넥터와 다수의 테스크를 지닐 수 있는 워커를 한 개 또는 여러 개를 가지며 아키텍쳐를 형성하고 데이터를 처리한다.
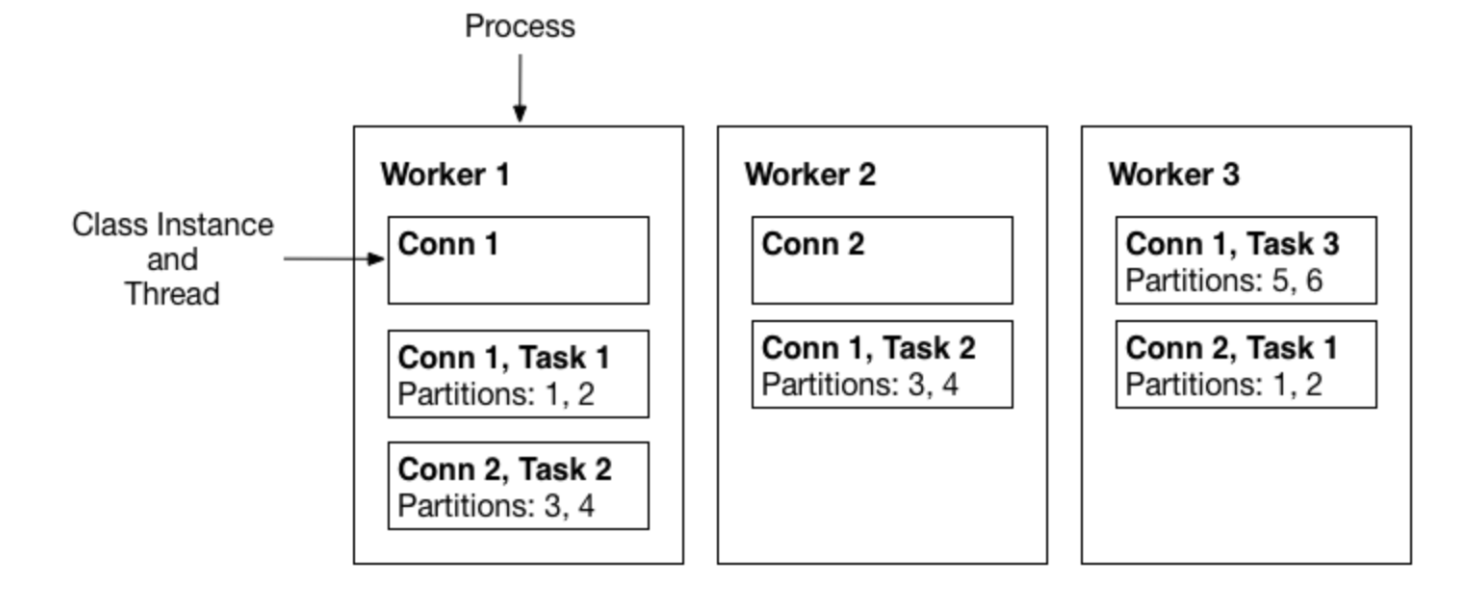
데이터 처리가 호출되면 워커 내부의 커넥터들에 의해 테스크들이 생성되고, 파이프라인이 구동된다. 그 후 테스크 내부에서는 외부 시스템의 메시지를 변화시키는 컨버터 처리가 발생한후 전송이 일어나는 원리이다.

카프카 커넥트의 모드
카프카 커넥트는 앞서 보았던 워커의 갯수에 따라 모드가 정해다.
만일 카프카 커넥트가 단일 워커로 이루어져있다면 단일 모드(standalone mode)라고 할 수 있다. 단일 모드의 경우 테스트 및 일회성 환경에 적합하다.
반대로 카프카 커넥트가 다수의 워커로 이루어져있다면 분산 모드(distributed mode)라고 할 수 있다. 분산 모드의 경우 실제 운영 환경으로 사용되며 REST API를 사용할 수 있다. 커넥트의 메타 데이터 정보를 저장함에 있어 카프카 클러스트를 이용할 수 있기에 장애에 유연하게 대처가 가능한 장점이 있다.
카프카 커넥트가 제공하는 REST API
카프카 커넥트를 보다 쉽게 사용하기 위해 REST API를 사용할 수 있다. 카프카 커넥트가 제공해주는 REST API로 관리자는 카프카 커넥트를 운영 관리할 수 있다.
✔︎참고. REST API 요청시 Content-Type, Accept 요청 헤더에 application/json 명시 필요
| API 옵션 | 설명 |
| GET / | 커넥트 버전과 클러스터 ID 확인 |
| GET /connectors | 커넥터 리스트 확인 |
| GET /connectors/커넥터 이름 | 커넥터 상세 내용 확인 |
| GET /connectors/커넥터 이름/config | 커넥터 config 정보 확인 |
| GET /connectors/커넥터 이름/status | 커넥터 상태 확인 |
| PUT /connectors/커넥터 이름/config | 커넥터 config 설정 |
| PUT /connectors/커넥터 이름/pause | 커넥터 일시 중지 |
| PUT /connectors/커넥터 이름/resume | 커넥터 다시 시작 |
| DELETE /connectors/커넥터 이름 | 커넥터 삭제 |
| GET /connectors/커넥터 이름/tasks | 커넥터의 태스크 정보 확인 |
| GET /connectors/커넥터 이름/tasks/태스크 ID/status | 커넥터의 특정 태스크 상태 확인 |
| POST /connectors/커넥터 이름/tasks/태스크 ID/restart | 커넥터의 특정 태스크 재시작 |
출처
https://debezium.io/documentation/reference/1.3/architecture.html
https://getto215.gitbooks.io/kafka-0-10-2/content/8kafka-connect.html
https://cjw-awdsd.tistory.com/53
https://always-kimkim.tistory.com/entry/kafka101-connect